

Last Updated: January 23, 2026
If you’re burning through Clay credits faster than expected, you’re not alone. That’s why I set out to scour LinkedIn to find 50 of the most experienced Clay experts. I asked each of them: What’s the best way to make sure I don’t waste a ton of money on Clay?
I got a lot of answers (some even bluntly told me: just use alternatives), but these were the 7 most popular ones I got. I linked to the Linkedin profiles of some of these experts, if you want to ask them any questions!
- 1. Test Everything in Sandbox Mode First
- 2. Reorder Your Enrichment Waterfall (Cheapest First)
- 3. Start with Companies, Not People
- 4. Write Better AI Prompts (Use Structured Formatting)
- 5. Optimize Your OpenAI Costs (Use Cheap Models for Research)
- 6. Set Up “Only Run If…” Conditions
- 7. Know Your Strategy Before You Build
1. Test Everything in Sandbox Mode First
Here’s a scenario that’s happened to basically every Clay user: you’re building a workflow, you accidentally run it on thousands of rows, and suddenly you’re watching your credits evaporate in real-time. Panic mode activated.
Clay recently added a feature called “sandbox mode” that solves this problem. Patrick Spychalski, co-founder of The Kiln (a Clay agency), calls it “a must-have feature” and notes that just about every Clay user has made costly mistakes in their tables before this feature existed.
Here’s how it actually works:
First, you go to your Clay table, click on “Actions” and go to “Turn on sandbox mode”.
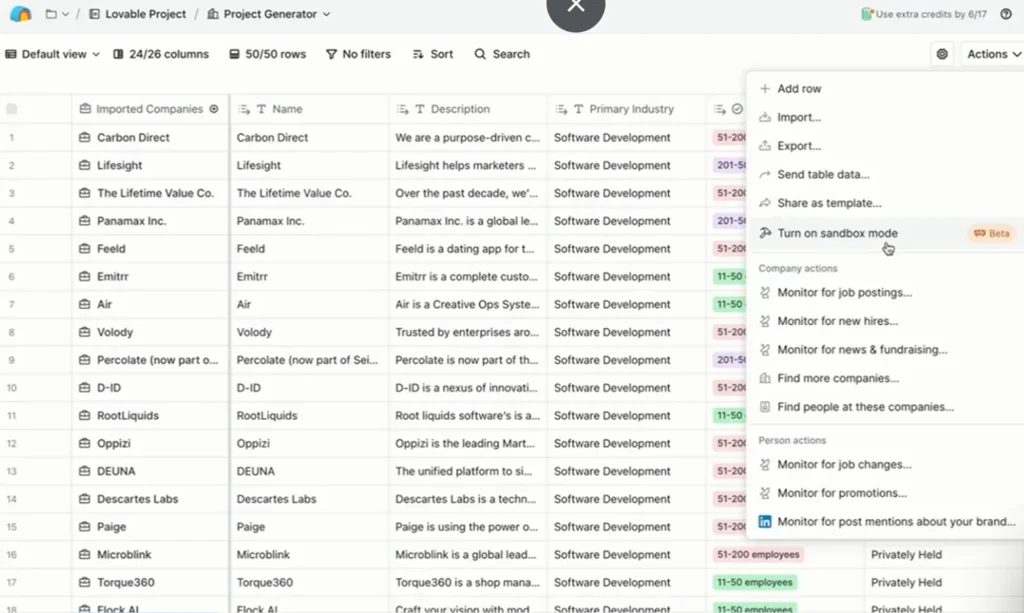
Sandbox mode creates a testing environment with a copy of your data (starts with your top 10 rows, max 50 rows). You can build out your entire workflow-adding enrichments, setting up waterfalls, configuring AI prompts-all while your production table stays locked and protected.

Here’s the important part: Enrichments in sandbox mode don’t automatically consume credits. You’re working with real enrichment capabilities, but the system won’t charge you unless you manually choose to run specific cells or columns.
Think of it like a rehearsal space before the main performance. You can experiment, test your logic, make mistakes, and figure out what works-all without accidentally burning through your credit balance.
Once you’ve confirmed everything works the way you want, you hit “Publish” to apply those configurations to your full production table. Then you run it on your complete dataset (this is where credits actually get used).
Why the 50-row limit matters: Some people ask, “Why not just do everything in sandbox mode?” The answer is simple-most real Clay use cases involve hundreds or thousands of rows. The 50-row cap makes sandbox perfect for testing workflow logic, but you’ll need to move to production for actual scale.
The real value? Preventing the nightmare scenario of accidentally running a misconfigured enrichment on 5,000 rows when you only meant to test it on 5. That’s where people blow through thousands of credits in seconds.
Kuldip Parmar, a lead generation expert, emphasizes that running bulk enrichments without testing first is one of the costliest mistakes Clay users make. His advice? Always run just 3 rows first to check the enrichment quality, and if anything looks off, make changes before running other columns.
As one user put it: “Sandbox mode = Staging, All Data mode = Production.” If you’re new to Clay, use this feature liberally. It’s your best friend.
2. Reorder Your Enrichment Waterfall (Cheapest First)
When you set up an enrichment waterfall in Clay, the platform automatically suggests a bunch of data providers. But here’s the thing: it doesn’t necessarily put them in the most cost-effective order.
Each provider shows a credit cost next to it. Some might cost 5 credits, others might cost 10 credits for the same type of data. If you don’t reorder them, you might be paying triple what you need to.
The fix is dead simple: rearrange your providers so the cheapest ones run first. If a provider is charging way more than the others for similar data quality, just remove it from your waterfall entirely.
Think of it like shopping-you wouldn’t pay $10 for something you can get for $3 somewhere else, right? Same principle applies here.
As an example, here’s the default order for mobile phone enrichments. As you can see, it has Forager and Prospeo listed in the first 2. Both of them consume 10 credits.
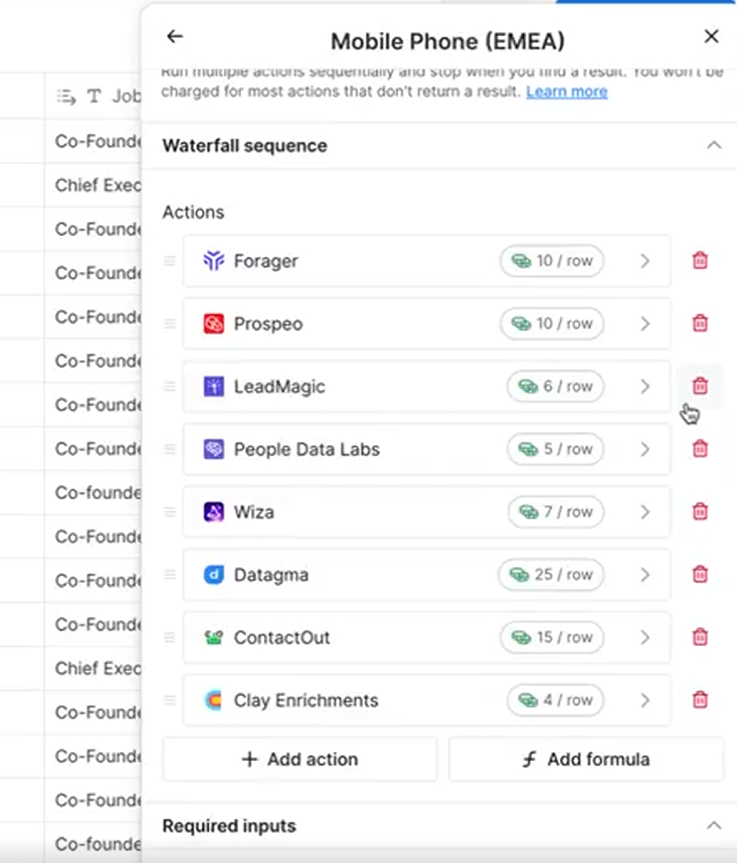
The most cost-efficient order, however, would be to use Clay enrichments 1st, then PeopleDataLabs, then LeadMagic, Wiza, etc. In short, you should use the provider with the least credits first. If Clay finds the data in the first step, you’ll consume fewer credits. If it can’t, it consumes 0 credits and moves on to the next data provider.
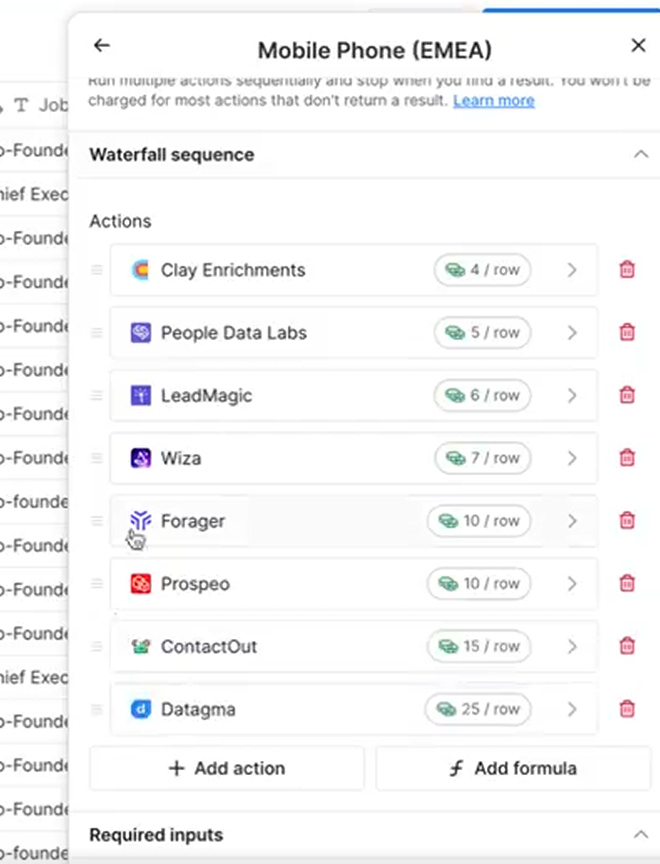
Patrick Spychalski notes that simply reordering providers is a mistake many first-time Clay users make, and it costs them valuable credits. Multiple experts report that organizing workflows in “ascending order of credits” is a habit that pays dividends over time.
3. Start with Companies, Not People
Here’s a strategic mistake that costs more than people realize: starting your workflow at the wrong level.
If you begin by building a list of individual people and enriching their contact information, you might end up paying to find emails for people at companies that don’t even fit your target profile.
Kuldip Parmar identifies this as Mistake #1 in his Clay workflow analysis. When you start with people, he explains, you must enrich both the company and the contacts, which doubles the Clay credits spent.
The smarter approach: start with company-level filters and enrichments first. Validate that companies meet your ICP criteria before you ever touch individual contacts. This prevents you from enriching contacts at companies you don’t actually want to target.
The workflow should look like this:
- Build your company list
- Enrich and filter companies (industry, size, tech stack, etc.)
- Filter down to only companies that match your ICP
- THEN find and enrich individual contacts at those companies
This simple reordering can cut your enrichment costs dramatically because you’re only paying for contacts at companies you actually care about. As Parmar notes, starting by building your list from companies first, then enriching the related contacts, saves credits and keeps data cleaner.
4. Write Better AI Prompts (Use Structured Formatting)
One of the most common mistakes Clay users make with AI is poor prompting. And it’s costing them both credits and quality results.
Jacob Tuwiner, a HubSpot and Clay expert, explains that generic prompts like “write me a sales email” are where most people go wrong. Instead, AI should be used for specific, targeted use cases with proper structure.
Kuldip Parmar breaks down the exact structure that works: Input → Action → Output → Prefix → Example. Clay AI, like any other LLM, needs a proper structural prompt. Ignoring this results in unsure outcomes or outputs that are completely different from what you expected.
Tom Veysey, a Clay expert, takes this even further. He points out that if you’re still letting Claygent (Clay’s AI web scraper) output free text, you’re setting yourself up for messy data-multiple data points jammed into one cell, needing another AI formula to extract info from your AI formula, and outputs you can’t actually act on without fixing first.
His solution? Get Claygent to output JSON schema. Clay parses it straight into columns with no manual cleanup needed. Each field has its own home in your table, the structure stays identical across every run, and missing info shows as null instead of random “n/a” or “unknown” guesses.
The best part? Clay has an “auto-generate JSON schema” button, so there’s really no excuse not to use it.
Real-world example: John Terrone shares how he almost tanked an outreach campaign because Claygent kept telling him a dental practice had 2 locations when they clearly only had 1. The AI was reading an address buried in HTML code-invisible to actual visitors. After refining his prompt to specify “Office locations must be VISIBLE on the website, not buried in code strings,” he got perfect accuracy.
The lesson? Clay lets you iterate until your data is bulletproof. Test, refine, perfect. Don’t skip the QA step.
5. Optimize Your OpenAI Costs (Use Cheap Models for Research)
This one could save you $14,000+ on OpenAI spend. Yes, really.
Jacob Tuwiner breaks down a common mistake that’s costing Clay users massive amounts of money: using expensive models like GPT-4o with Claygent to scrape and output finalized data.
Here’s why it’s a huge problem: AI models charge via tokens. The more tokens (think: the amount of info the AI is processing), the more you pay. Web scraping uses HUGE context windows, so using an expensive model like GPT-4o for such a task can cost $0.05-$0.10 per call. A few of those AI prompts add up fast to $0.30 per record. Multiply that by 50,000 records, and you’re out $15,000.
The simple trick to slash those costs by 90%:
- Use a cheap model like GPT-4o-mini with Claygent
- Ask the Claygent AI to return a summary paragraph of its findings rather than formatting the answer into a final output (costs only $0.001-one tenth of a penny. Now your $15k bill is reduced to $50)
- Pass the 4o-mini research output into another GPT prompt that uses GPT-4o for the final output. This significantly reduces the context window on the more expensive model, saving you tons of money ($0.001 instead of $0.05 per call)
For example, if you’re categorizing custom industries, use GPT-4o-mini to generate the summary paragraph, then use GPT-4o to take that summary and bucket it into the right category. This slashes your total cost from $15,000 down to $300.
Additionally, many Clay experts recommend connecting your own OpenAI API key rather than using Clay’s native integration. When you use Clay’s integration, you’re paying Clay’s rate. Connect your own API key directly to OpenAI, and you pay OpenAI’s rate instead-which is significantly cheaper, especially if you’re running lots of AI-powered enrichments.
6. Set Up “Only Run If…” Conditions
This one’s a bit more advanced, but it’s worth understanding early.
Clay lets you add conditional logic to your enrichments-basically, rules that say “only run this enrichment if X condition is met.” This prevents you from wasting credits on data you don’t actually need.
As an example, let’s say you have a table already with contacts and their business email addresses. Some rows may have missing emails and you want to add an enrichment column that attempts to get their personal email for those with missing emails.
What you would do, after you add your enrichment column, would be to scroll down to “Run Settings”, and click on that.
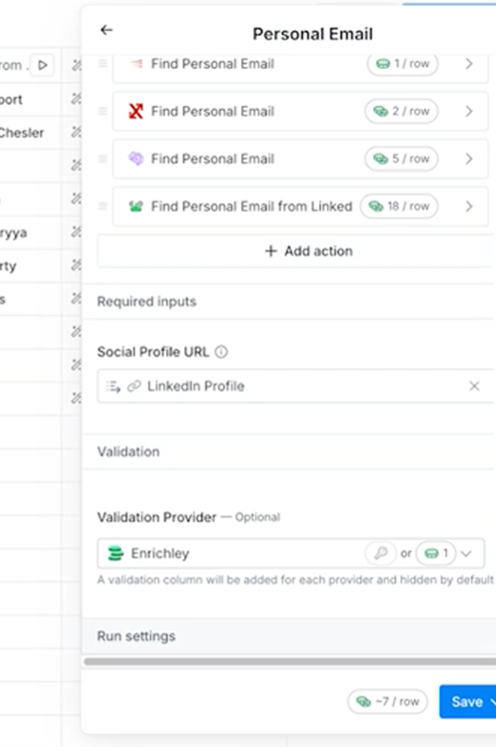
You’ll then see a screen pop-up where you can specify the conditional formula that must be true for the enrichment to run. Here, you can see I told Clay to only run this enrichment if “Work email” is blank.
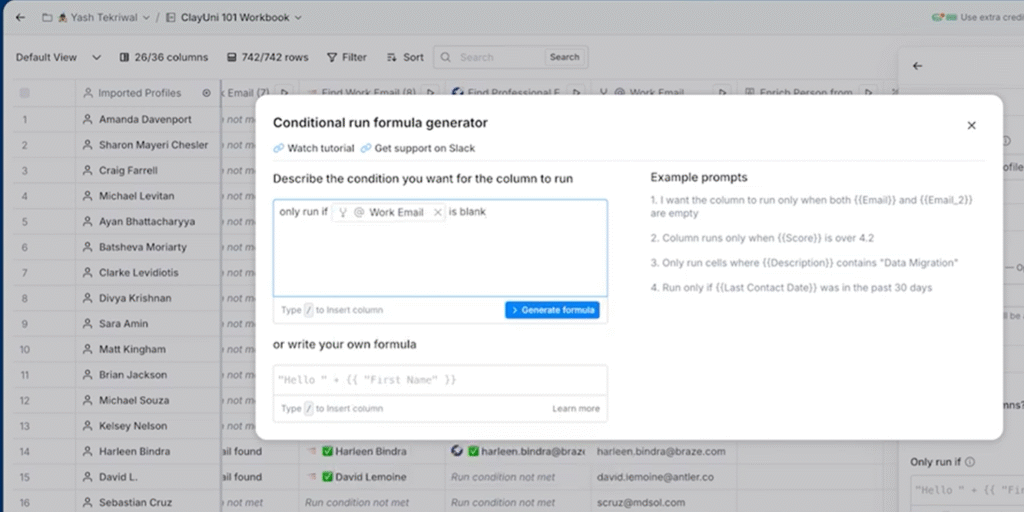
One user shared their approach: “I’m building in a checkbox at the very beginning and setting a conditional run field. No more wastage.”
The key insight here: don’t enrich everything just because you can. Be selective. Your credit balance will thank you.
Pro tip: Another smart strategy mentioned by multiple users is to validate emails before running expensive personalization enrichments. Jacob Tuwiner found in one audit that a company was spending $0.16 per email instead of less than $0.01 per email, and 50% of the time they were paying for a BLANK email cell. Always validate first, personalize second.
7. Know Your Strategy Before You Build
Kuldip Parmar identifies “Starting Without a Clear Strategy” as one of the top mistakes that wastes credits.
When you don’t have a clear outcome expectation in mind, you start confused in the process and waste more credits than expected. His solution? Before starting any Clay assignment, always write down the desired outcome in your notes. This helps you have better clarity in the process.
Marina Ghilchik, a GTM strategist, expands on this concept. She sees organizations constantly making the same mistake: they automate before they diagnose. Everything becomes a flowchart. The team gets scared of burning credits, and then Clay takes the blame for something it didn’t do.
As she puts it: “Clay isn’t broken. Their thinking is.” The worst part? Teams only use 10% of what Clay can do and overpay to underdeliver because no one’s asking the right questions:
- What should we automate?
- What needs to stay human?
- What drives actual results?
Her advice? Don’t just hire a builder. Hire a strategist. Someone who knows when to push AI and when to pull back. Someone who designs for outcomes, not clicks. Someone who builds with brains, not just buttons.
Bonus Tips from the Clay Community
A few other quick wins that came up repeatedly:
Always QA your data before running at scale. Kuldip Parmar notes that skipping quality checks is a major mistake. Bad or outdated data causes bounces, lowers response rates, and reduces campaign success-all of which can be removed easily. Use formula fields to remove unnecessary data, then verify using external tools like Neverbounce.
Use formulas to normalize data first. Clean up company names, standardize domains, and fix formatting issues using free formula columns before you start enriching. This prevents duplicate enrichments on the same company just because the name was formatted differently.
Track your credit usage by workflow. Some users mentioned building systems to track which tables and workflows consume the most credits. This helps you identify where you’re overspending and where you can optimize.
AI emails need granular prompts to work. Jacob Tuwiner explains that those who say “AI cold emails don’t work” are right-when AI isn’t used correctly. AI’s efficacy comes down to the granularity with which you write prompts, input data, and output rules. In a recent campaign, proper AI usage halved the number of emails sent while doubling positive responses-a 5x boost in positive response rate.
The Bottom Line
Clay is an incredibly powerful tool, but it’s easy to rack up costs if you’re not intentional about how you use it.
The common thread across all these tips? Slow down and think before you enrich.
Test in sandbox mode. Order your providers by cost. Start with companies before people. Write structured AI prompts. Use cheap models for research, expensive ones for final output. Set up conditional logic. Know your strategy before you build. And always validate your approach on a small batch before going all-in.
As one seasoned Clay user wisely noted: “Double-checking inputs before bulk enrichment is key for clean data.”
A little upfront planning can save you thousands in credits-and help you build better, cleaner workflows in the process. The experts who’ve been using Clay for years all have one thing in common: they treat credits like a budget, not an unlimited resource. Every enrichment should have a purpose, and every workflow should be tested before it scales.
Take the time to build smart, and your credit balance will last a lot longer.
Special thanks to all the Clay experts on Linkedin that chimed in with their advice!
📊 See which companies use these tools
Explore adoption data for Clay and related data enrichment tools:


