

Last Updated: February 18, 2026
As someone who has done a lot of labor studies, and also analyzed job postings for GTM signals, I’ve explored a lot of different job posting providers. And I’ve seen which ones work best for which use cases.
For example, if you’re a sales team using job postings to find prospects, there’s absolutely no need to pay enterprise prices for the exact same data that other inexpensive providers provide (unless you like wasting money). But, if you’re doing serious labor market analysis, you don’t want to go with a cheap data provider that doesn’t have much historical, global data, or job postings data enriched with skills.
My guide covers everything from self-serve providers to more enterprise solutions. For each option, I’ll show you what data they provide, how far back it goes, what it costs, and who it’s best for. Complete with screenshots so you know I’ve done my homework.
- Bloomberry – most inexpensive option for all use cases (Free To Try)
- CoreSignal – best if you need overall company intelligence (Free To Try)
- CrustData (Requires Demo)
- Linkup (Requires Demo)
- Revelio – best for talent/skills intelligence (Requires Demo)
- Lightcast – best for workforce intelligence (Requires Demo)
- Revealera – best for public investors (Requires Demo)
At-a-Glance Comparison
| Provider | Best For | Cost per Job | Data Source | History | Self-Serve | Free Trial |
|---|---|---|---|---|---|---|
| Bloomberry | Budget-conscious GTM & sales teams | $0.003 – $0.006 | Company websites | 2020+ | ✅ | ✅ |
| Coresignal | Teams needing multi-source coverage + enrichment | $0.005–$0.196 | LinkedIn, Indeed, Glassdoor, Wellfound | Varies | ✅ | ✅ |
| CrustData | AI agents & teams needing real-time alerts | Undisclosed | LinkedIn + job boards | Limited | ❌ | ❌ |
| LinkUp | Enterprise labor market research | Undisclosed | Company websites | 2007+ | ❌ | ❌ |
| Revelio Labs | HR teams & researchers needing skills/talent analytics | Undisclosed | Multi-source + company sites | 2008+ | ❌ | ✅ |
| Lightcast | Large orgs doing workforce planning | Undisclosed | Multi-source + govt data | 2010+ | ❌ | ❌ |
| Revealera | Hedge funds & quant investors | Undisclosed | Company websites | 2018+ | ❌ | ✅ |
1. Bloomberry – least expensive versatile option
Pros: Least expensive option, costing $0.006/job posting in the lowest volume tier
Cons: Lacking skills enrichment. Only crawls company websites, not Linkedin jobs.
What does Bloomberry offer?
Bloomberry is a new job postings API from Revealera, their parent company. Revealera has been providing job data for hedge funds since 2020, and Bloomberry is their self-serve option for GTM teams, sales platforms, and niche job boards.
Bloomberry’s API does 2 main things: One is to get job postings for a company or keyword/job title. You can pass in a company domain (ie microsoft.com), or a keyword, a date range and it’ll return all job postings that fit your criteria.
When I tried their API and passed in microsoft.com, I got back a list of job postings posted by Microsoft, sorted by most recent first.
Each job posting came with the job title, URL, salary ranges (if public), a “normalized job title”, region/country, the actual company (their domain and Linkedin page), and the full-text job description. As you can see from the screenshot below, it’s all straightforward from the field names what I’m getting back.

Second, is to get actual trends. As someone who does a lot of research on AI, I’m particularly interested in how many job postings mention “AI governance” over time. So I tried passing “AI governance” in the search query and their API returned the # of job postings per month mentioning that keyword since January 2020.
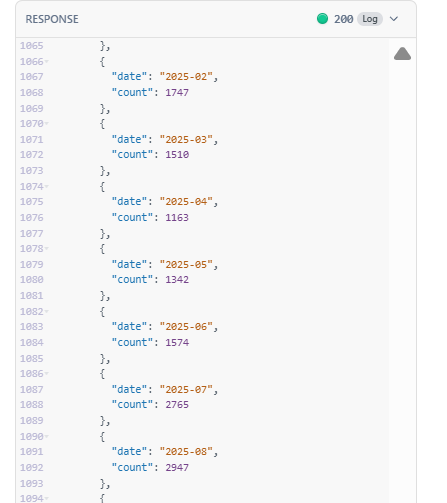
The data can be returned by either JSON format or CSV format. Unfortunately, at this time they don’t offer bulk downloads such as .zip files
What is the source of Bloomberry’s jobs data?
Bloomberry directly crawls jobs from company websites. So if a company (ie a SMB) doesn’t post jobs on their Linkedin page, and only on their website, Bloomberry still is likely to find it.
This has its pros and cons. The negative side is that some companies exclusively post jobs on their LinkedIn page, and never on their website. So Bloomberry will inevitably lack data for those companies.
The plus side is that Bloomberry will rarely show reposted jobs (jobs that were posted months ago and reposted again on Linkedin). And it will rarely show jobs from recruiting agencies that often post on Linkedin. So if you absolutely need to find job postings that are *new* and from actual companies, then Bloomberry’s data is perfect for that.
What is their coverage like?
Bloomberry crawls over 2.5 million job postings a month, globally – again, directly from the company website. They cover every single industry from financial services, tech, non-profits, government institutions and universities.
How fresh and accurate is their data?
Bloomberry crawls company websites for jobs twice a day, so you’re likely to see a new job posting appear in their API within 24 hours of it being posted.
What’s their major limitation?
Bloomberry only offers an API that returns data in JSON or CSV format. While you can definitely query their API to get historical data, they don’t offer a bulk download in zip format.
In addition, although you can search job postings by skill (or any keyword that might appear in the description ie. Python, or Revops), if you want to know all the skills mentioned in a job posting, you need to parse it out from the full-text job description yourself. Or you’ll need to use an LLM like OpenAI to do it for you.
In addition, since it doesn’t crawl Linkedin data, it inevitably will miss data from companies that post exclusively on Linkedin (shame of you, whoever you are!).
Lastly, their history only goes back to 2019-2020 for most companies. If historical data before than is important to you (ie for labor market research), then Linkup or Lightcast probably would serve your needs better.
How much does Bloomberry cost?
Bloomberry is the most inexpensive option out of all the paid providers, with costs starting at $0.006/job posting, and scaling down as your usage goes up. That means if you just need 100K jobs, the total costs will be $600.
It’s also 100% self-serve, as you can try their API without even signing up to see what fields you’re getting back and how well it fits your use case.
Who is Bloomberry best for?
Bloomberry is best for anyone who has a lean budget and doesn’t want to commit a lot of money initially. At just $0.006/job posting, Bloomberry has the least expensive pricing out of all the providers, and anyone from sales teams to GTM tools can use it without committing to a large enterprise contract.
2. Coresignal – multi-source web data with a premium price tag
Pros: Self-service platform with free trial, multi-source datasets combining LinkedIn, Indeed, Glassdoor, and others.
Cons: Cost much more compared to alternatives offering similar data
What does Coresignal offer?
Coresignal is a B2B web data provider founded in 2016, primarily focused on employee profiles, company data, and job postings. They have 823M+ professional profiles, 74M+ company records, and 399M+ job postings.
For job postings specifically, Coresignal offers two distinct API products, which can be quite confusing at first glance:
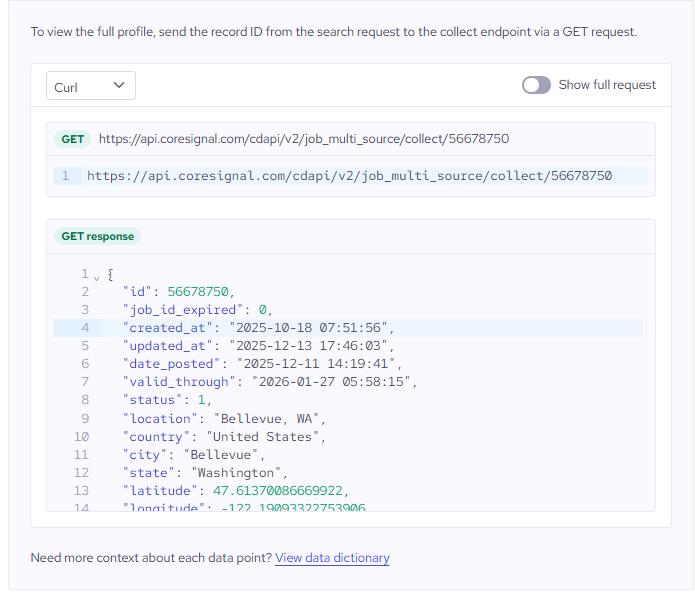
Base Jobs API – Single-source job postings scraped from one platform at a time. Each record includes ~20 data points: job title, description, location, employment type, salary (when available), company name, posting date, and status (active/inactive). You can search using filters like employment_type, location, company_name, or last_updated_gte for date ranges. Costs 1 credit per record.
Multi-source Jobs API – Deduplicated job postings aggregated from multiple job boards (LinkedIn, Indeed, Glassdoor, Wellfound). Each record includes 65+ data points – everything in Base plus:
- Hiring company enrichment: HQ location, industry, company size, keywords
- Recruiter information: name, title, profile
- Job metadata: department, management level, seniority, whether it’s a decision-maker role, remote/hybrid status, shift schedule, urgency flags
The Multi-source API costs 2 credits per record but saves you the work of deduplicating across platforms and enriching with company data yourself. It also gives you a lot more coverage, as it’s aggregating across more than 1 job board (although, in my experience if a job is in Indeed/Glassdoor/Wellfound, it’s probably in Linkedin as well)
Which one should you choose?
Go with Base Jobs API if:
- You’re building a job board or aggregator and just need raw listings
- You only care about one source (e.g., just LinkedIn jobs)
- Budget is tight and you can handle deduplication yourself
- You need maximum volume at the lowest cost per record
Go with Multi-source Jobs API if:
- You’re doing sales prospecting and need recruiter contact info
- You want to know which companies are hiring without seeing the same job 3x across platforms
- You need company context (industry, size, HQ) alongside job data
- You’re building an AI/ML model and want cleaner, enriched training data
Honestly, for most use cases beyond simple job board aggregation, the Multi-source API is worth the 2x cost. De-duplicating job postings is really important for almost all use cases. Here is a good example below I pulled from Coresignal where it found the same job posted on October 17, 2025, which it detected as a duplicate of an old job posted on Indeed on September 21, 2025.
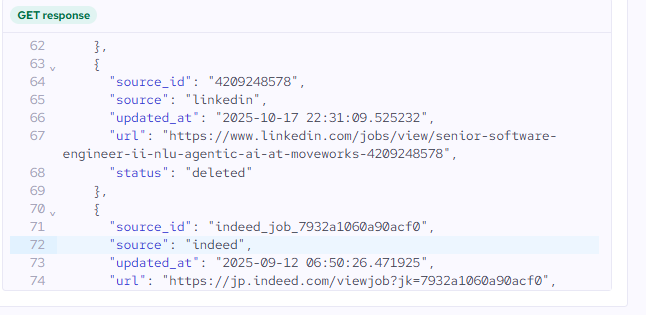
With the multi-source API, you would know the Linkedin job wasn’t an actual new job.
What is the source of Coresignal’s job postings data?
As mentioned, Coresignal scrapes professional social networks and business-related sites including Glassdoor, Indeed, Wellfound, and LinkedIn.
What is their coverage like?
For the multi-source dataset, their coverage is pretty vast since they’re covering 4 major job board sources. As they don’t scrape directly from company websites, they’ll inevitably miss job postings from companies that don’t post directly on Linkedin or any aggregators.
How fresh and accurate is their data?
For LinkedIn job postings, Coresignal only renews active listings. API access provides real-time updates as new listings appear.
What’s their major limitation?
In my opinion, there isn’t a major “limitation” per se. My main complaint is that Coresignal simply charges a bit too high a premium for job postings data.
How much does Coresignal cost?
Coresignal offers a self-service platform with transparent API pricing. New users get 200 free Collect credits and 400 free Search credits for a 14-day trial. After that, you have to choose a pricing plan, which differs on the $ per credit:
The credit system works like this: 1 Collect credit = 1 data record retrieved. Multi-source data costs 2 credits per record. Search credits (for filtering/querying) are included free at 2x the Collect credits.
Let’s do the math on what this actually costs:
If you want to pull 10,000 job postings per month, you’d need the Pro plan at $800/month – that’s $0.08 per job posting. Want to track 50,000 jobs monthly? That’s the Premium plan at $1,500/month, or $0.03 per posting. If you need multi-source enriched records (which cost 2 credits each), those numbers double.
The pricing per credit does go down per month, the more you spend. But even at the highest tier, the cost per posting is still $0.005 (and you probably need to spend more than $1500+ to reach this cost).
For comparison on the costs, Bloomberry charges $0.006 per posting at its lowest tier ($199/month), with costs going down much further the more you pay. And their data is already de-duplicated, since they take jobs directly from company websites.
So Coresignal is roughly 2-10x more expensive than alternatives for similar raw job posting data, albeit with more coverage, and more enriched fields (such as hiring manager information).
Who is Coresignal best for?
If you need a polished, pre-cleaned dataset with vast coverage of multiple job boards with company enrichment, and budget isn’t the primary concern, Coresignal would be a good solution for you.
4. Crustdata – real-time job postings data
Pros: Real-time data with “Watcher” webhooks for instant alerts, strong focus on AI agent use cases, and unified data from 16+ sources.
Cons: Pricing not publicly disclosed, and primarily focused on company/people signals rather than pure job postings.
What does Crustdata offer?
Crustdata is a newer entrant in the B2B data space, founded in 2023 and backed by Y Combinator. Their pitch is simple: most B2B data providers offer stale, monthly-updated data that doesn’t work for AI agents. Crustdata aims to fix that with truly real-time data.
The company positions itself as the “data layer for AI agents” – powering AI SDRs, recruiting platforms, and investment deal sourcing tools. They monitor over 60 million companies and 1 billion individual profiles, pulling structured signals and mapping them to entities in real time.
Their product suite includes:
- Company Enrichment & Search APIs – firmographic data with 200+ fields per company
- People Enrichment & Search APIs – professional profiles with job history, skills, education
- Jobs API – structured job posting data with 30+ data points per listing
- Posts API – social media activity tracking
- Watcher API – the standout feature: webhook-based alerts for events like job changes, funding rounds, headcount shifts, and new job postings
The Watcher API is what differentiates Crustdata. Instead of polling for changes, users subscribe to events and get instant notifications when something happens. I’ll expand on this a bit more down below.
What is the source of Crustdata’s job postings data?
For job postings specifically, they pull from LinkedIn and other major job boards, enriching each listing with company context. The Jobs API provides filters like job title, category, location, number of openings, and workplace type (remote/hybrid/onsite).
What is their coverage like?
Since they use Linkedin and other major job boards, their coverage is pretty good. But since they don’t crawl company websites directly, they’ll miss companies that don’t post jobs on Linkedin.
How fresh and accurate is their data?
CrustData offers instant webhooks when a company posts a new job postings matching your search.
That means instead of polling their API repeatedly to check for new job postings, you subscribe to specific triggers and get instant notifications pushed to your endpoint when they happen.
Some example webhooks you can set up:
- New job posting by keyword: Get notified when any company posts a job containing “AI Engineer” or “Head of Sales” or whatever you’re tracking
- New job posting by location: Alert when companies start hiring in specific cities or countries
- Company starts hiring in a new country: Detect international expansion signals
- Headcount growth by department: Track when engineering or sales teams start scaling
Most job data providers work on a “pull” model – you query their API daily, get a snapshot, and diff it yourself to see what’s new.
Crustdata’s webhooks flip this to a “push” model. Set your filters once (e.g., “notify me when any Series B fintech posts a VP of Engineering role”), and you get notified the moment it happens – not 24 hours later.
However, there’s something you should keep in mind. Their webhooks notifies you when they detect a new job posting. But that *doesn’t necessarily mean* they notify you as soon as that job posting appeared. As an example, a company might’ve posted a job 12 hours ago. Crustdata detected it just now and pushed a webhook to notify you.
The webhook eliminates your polling lag, but not their data collection lag. “Real-time” is marketing language – it’s really “as fast as their crawl schedule allows, pushed to you instantly.”
What’s their major limitation?
You have to book a demo to get pricing, which suggests enterprise-level costs. If you’re a startup, small sales team, or individual researcher, this friction alone might be a dealbreaker.
Job postings also aren’t their core focus: Their product suite is built around company and people intelligence – job postings are one signal among many (funding, headcount, social posts, news mentions). Providers like Bloomberry, Revealera, or LinkUp are purpose-built for job data and likely have deeper coverage and better deduplication for that specific use case.
How much does Crustdata cost?
Crustdata doesn’t publish pricing on their website, which is a negative. But the fact a demo requires a call certainly means Bloomberry is a more cost efficient option.
Who is Crustdata best for?
Crustdata is ideal if you need real-time job posting alerts, which sounds awesome on first glance, but really isn’t something I would pay a premium for.
For starters, polling isn’t expensive if you’re smart: If you construct your API calls to “give me jobs posted since the date/time of the most recent job I retrieved previously” via API, the cost is trivial. You could poll every minute, or even every second because this will only give you the most recent jobs, not previously seen ones.
Hourly vs “instant” also doesn’t matter for many use cases: If a company starts hiring in Germany for the first time, does it matter if you find out at 9:00am vs 9:47am? The insight is strategic, not time-critical. You’re not racing anyone.
Lastly, Crustdata’s data isn’t truly real-time anyway: As I said, their crawler might only hit that Linkedin jobs page once a hour, or once a a day. So the webhook fires “instantly” after their crawl, but that could still be 12-24 hours after the job was posted.
Where webhooks genuinely help:
- You don’t have to build/maintain the polling + diffing infrastructure yourself
- You don’t have to store state (“what was the last job ID I saw?”)
- Cleaner architecture if you’re building event-driven systems
But that’s a convenience/engineering benefit, not a speed benefit. If you’re willing to pay for that, then Crustdata and their webhooks is for you.
5. LinkUp – enterprise-grade with direct company sourcing
Pros: Crawls directly from company websites (not job boards), monitors and fixes broken scrapers within 24 hours, long historical depth since 2007.
Cons: Enterprise pricing (requires demo), recent acquisition by GlobalData may impact innovation, no self-serve option for smaller users.
What does LinkUp offer?
LinkUp is one of the OG job data providers, having been in business since 2007. I’ve even used them back in the day to find actual jobs to apply to. They used to have a simple UI where you do a search and it’ll show you all the jobs in their database. I don’t see it anymore, so I assume they removed it recently.
Their dataset includes over 200 million historical job postings dating back to 2007, with approximately 5 million daily active job listings.
Each posting includes standard fields like job title, company, location, salary (when available), and full job descriptions. They also provide their data through multiple products including their RAW dataset (for direct API access) and Compass (their visualization dashboard).
What is the source of LinkUp’s jobs data?
Like Bloomberry, LinkUp exclusively scrapes job postings directly from company career pages. They’re not aggregating from job boards like Indeed or LinkedIn, which means they avoid many of the data quality issues that other Linkedin scrapers face.
You get no reposted jobs from recruiters, no duplicate listings across multiple job boards, and no jobs that were posted months ago but show up as recent.
Linkup is enterprise-grade – they got a support team, and a QA team.
Their notable strength is their monitoring system. Companies frequently change their ATS or update job page formats, which can break scrapers.
LinkUp fixes this by maintaining a “broken scrapes queue” that flags issues and notifies their team. Public companies are typically fixed within 24 hours, and clients can escalate specific companies if needed.
What is their coverage like?
LinkUp crawls over 60,000 public and private companies across 195 countries. They maintain approximately 5 million daily active job listings, and their historical dataset goes back to 2007 with over 200 million total job postings.
Their coverage is particularly strong for large public companies and Fortune 500 firms, which makes sense given their focus on institutional clients.
How fresh and accurate is their data?
Because they monitor for broken scrapers and fix issues quickly (typically within 24 hours for public companies), their data freshness is generally reliable.
What’s their major limitation?
The biggest limitation is accessibility. LinkUp is an enterprise product that requires contacting sales for a demo (ugh, I know).
There’s no self-serve option, no public pricing, and no free tier to test the data quality before committing. This makes it impractical for individual researchers, students, small startups or small GTM teams.
Additionally, LinkUp was recently acquired by GlobalData in late 2024. While it’s too early to tell definitively, acquisitions often lead to shifts in product focus and a slowdown in innovation. I wouldn’t be surprised if their “robust QA process” suddenly becomes less of a priority.
How much does LinkUp cost?
As mentioned, LinkUp does not publish pricing publicly. You need to contact their sales team for a demo and custom quote.
Who is LinkUp best for?
LinkUp is built for large enterprises who need comprehensive, clean job posting data with a long history.
Their long historical depth makes them particularly valuable for economic research and labor market forecasting. While Bloomberry has data since 2020, you most likely need data for a much longer period for a more accurate analysis of labor market trends.
6. Revelio Labs – enterprise-grade workforce intelligence platform
Pros: Comprehensive workforce database combining multiple data sources, with deep skills and activity enrichment
Cons: Enterprise pricing (requires demo), no self-serve option for smaller users, complex product suite may be overkill for simple job postings needs.
What does Revelio Labs offer?
Revelio Labs positions itself as a “workforce intelligence” company rather than just a job postings provider, but they do have a job postings product.
Their flagship job postings product is COSMOS – a unified and deduplicated dataset covering over 4.1 billion current and historic job postings from 6.6 million companies. But unlike simpler job data providers, COSMOS is just one piece of their broader workforce analytics suite. Beyond job postings, Revelio offers workforce dynamics data (headcounts, inflows, outflows), which is arguably their main differentiating value.
Below is a dashboard from Revelio’s core product, where you can see just how much data they have on workforces. You can see the breakdown in geography, seniority, ethnicity and education levels of employees in Amazon, NVidia, Tesla and Meta. You can also compare granular data such as the growth rate, hiring rate and attrition rate of companies. This is really insightful data.
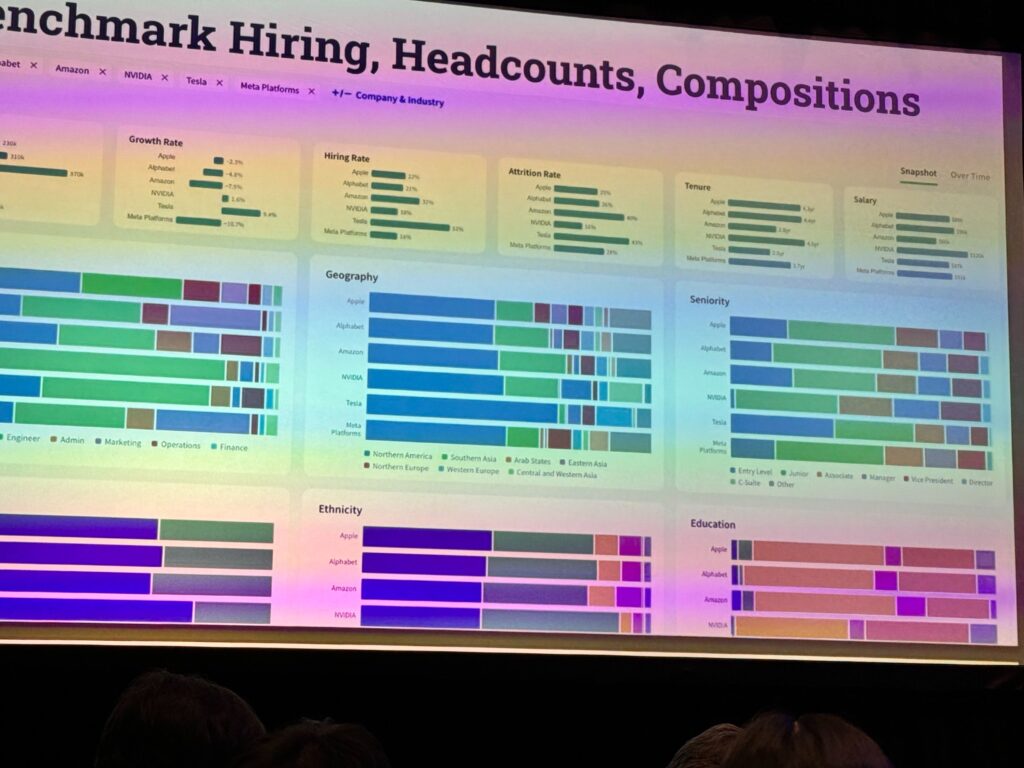
If you’re doing any sort of analysis on talent movement or talent intelligence, Revelio would be incredibly useful.
What is the source of Revelio’s jobs data?
Revelio sources from company websites, all major job boards, and staffing firm job boards.
They use a sophisticated deduplication process to handle the fact that the same job gets posted across multiple platforms. I imagine they have an algorithm that looks at similarities in the job description to filter the dups out.
What is their coverage like?
According to their documentation:
- 4.5M+ Companies – Entities are cleaned and mapped to subsidiary and holding companies. 1.1B+ Profiles – Resume text is absorbed and standardized to deliver a normalized view of all roles, skills, and activities.
- 5.2K+ Cities and states – Location is mapped to city, metropolitan area, state, and country.
- 3.4K+ Skills and activities – All aspects of a role are indexed to create hierarchical taxonomies.
How fresh and accurate is their data?
Job postings are continuously sourced, normalized, and mapped in a feed that refreshes daily.
Based on their LinkedIn posts, they’re quite vocal about data quality topics – they’ve published research on ghost jobs, analyzed how their data compares to official BLS numbers, and even launched RPLS as an alternative to government statistics.
What’s their major limitation?
The biggest limitation, like Linkup is accessibility. Revelio is an enterprise product built for institutional clients. They don’t publish pricing and you have to talk to a salesperson.
Unlike Bloomberry, there’s no self-serve option where you can just sign up and start pulling data. While they do offer a free trial, you’ll need to engage with their sales team to access it. If you just need basic job postings data for a small project, Revelio is probably overkill.
The breadth of their offering can also be a downside. If you only care about job postings, you’re paying for a comprehensive workforce intelligence platform when you might only need one piece of it. The learning curve for their taxonomies and data structures is steeper than simpler API-based providers.
How much does Revelio Labs cost?
As mentioned, Revelio does not publish pricing publicly. You’ll need to request a demo to get a custom quote based on your use case.
Based on their customer base and market positioning, expect enterprise-level pricing – this isn’t a product designed for individual researchers or bootstrapped startups. You’re going to have to pay a pretty penny.
Who is Revelio Labs best for?
Revelio is best suited for:
- Corporate strategists doing competitive intelligence on talent trends
- Large HR teams who want to benchmark their workforce against competitors
- Academic researchers (through WRDS) studying labor market dynamics
If you’re trying to understand workforce composition at a granular level, Revelio’s depth is unmatched. But if you just need a simple job postings feed, their complex platform is probably more than you need.
7. Lightcast – the industry standard for labor market intelligence
Pros: Most established player (20+ years), deepest historical data (back to 2007), industry-standard skills taxonomy, integrates government data with job postings, trusted by 67 of Fortune 100.
Cons: Enterprise pricing (requires demo), complex multi-product suite, overkill if you just need job postings data.
What does Lightcast offer?
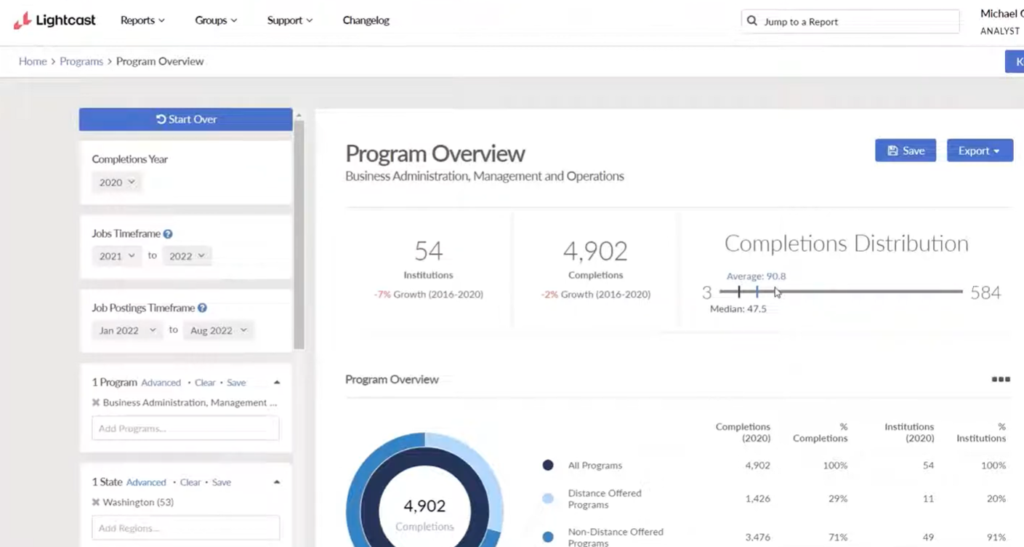
Lightcast is the 800-pound gorilla of labor market data. Formerly called Burning Glass, Lightcast has more than two decades of experience providing detailed information about occupations, skills in demand, and career pathways.
Like Revelio, Lightcast isn’t just a job postings provider – it’s a full labor market intelligence platform. They aggregate data from 160,000+ sources, including job postings, government reports, skills databases, compensation records, and professional profiles.
For job postings specifically, Lightcast job postings data is gathered by scraping over 220,000 websites worldwide with sophisticated deduplication that removes up to 80% of duplicates. Each posting gets enriched with dozens of data elements, including Lightcast job titles, occupations, companies, and detailed data about the specific skills, educational credentials, certifications, experience levels, and work activities required for the job.
What is the source of Lightcast’s jobs data?
Lightcast combines scraped job postings with government statistical data from BLS, Census Bureau, and state labor offices. Lightcast collects job postings worldwide from over 220,000 current and historical sources, including jobs boards and company websites. They don’t scrape Linkedin, as far as I can tell.
What is their coverage like?
Lightcast has massive scale – probably the biggets database of historical and current job postings out of everyone. They tout a database of 2.5 billiontotal job postings with US job postings data goes back to 2010 in their API.
Their international coverage is also massive – Lightcast has data on over 150 countries.
How fresh and accurate is their data?
Job postings are scraped, deduplicated, and added to the system every day.
What’s their major limitation?
Like Linkup and Revelio, Lightcast is enterprise-focused with no self-serve option for their core products.
One thing to note is that their heavy reliance on government data means some metrics can lag, especially recently during the US government shutdown.
How much does Lightcast cost?
Lightcast is expensive… like really really expensive.
They don’t publish pricing for its core enterprise products (Analyst, Developer APIs, and SaaS platforms) – you’ll need to request a demo. However, they do offer self-serve dataset purchases through AWS Marketplace with transparent pricing, so you can get some idea of their pricing based on their dataset pricing there.
Here is what I gathered from the AWS Marketplace:
Single-country datasets (12-month subscriptions):
- Base dataset: $16,500/year (Italy, Spain)
- With Lightcast taxonomies: $16,500–$22,000/year
- With raw data + taxonomies: $22,000–$27,500/year (varies by country)
Multi-country bundles:
- 5 countries (Italy, Spain, France, Germany, Switzerland): $71,500/year
- 5 countries with raw data: $90,200/year
- All 27 EU countries: $99,000/year
- All 27 EU countries with raw data: $115,500/year
You’re looking at over $100K/year for just EU data.
Who is Lightcast best for?
If you’re doing any sort of large scale workforce planning, Lightcast *might* be a feasible choice for you. For instance, if you’re a large organization like Microsoft and need to know where you should hire AI talent, or if you’re OpenAI and want to know which companies to poach AI talent from, I can see where Lightcast would be a worthwhile investment.
But again, if all you need is a list of job postings that mention a particular keyword, or from a particular company, Lightcast is going to be overkill for you.
8. Revealera – best for investment firms and hedge funds
Pros: 100% focused on job postings data with rigorous daily data quality checks, historical data back to 2018, transparent methodology, and reasonable pricing compared with competitors.
Cons: Smaller company universe than enterprise providers (~5000 companies), primarily serves financial services clients, less enrichment than Lightcast/Revelio
What does Revealera offer?
Revealera is a specialized data provider focused on hiring trends and product adoption signals, primarily serving hedge funds, investment managers, family offices, and systematic traders. They offer 2 core datasets:
Hiring Trends & Descriptions: Job opening counts and full posting data for 5000 + public and private companies, with daily snapshots going back to 2018.
Product/Skill Mentions: Tracks how often specific products (Datadog, Splunk, Salesforce) or skills (Python, Machine Learning) appear in job postings across ~20,000 companies. This is really useful for tracking vendor momentum or technology adoption.
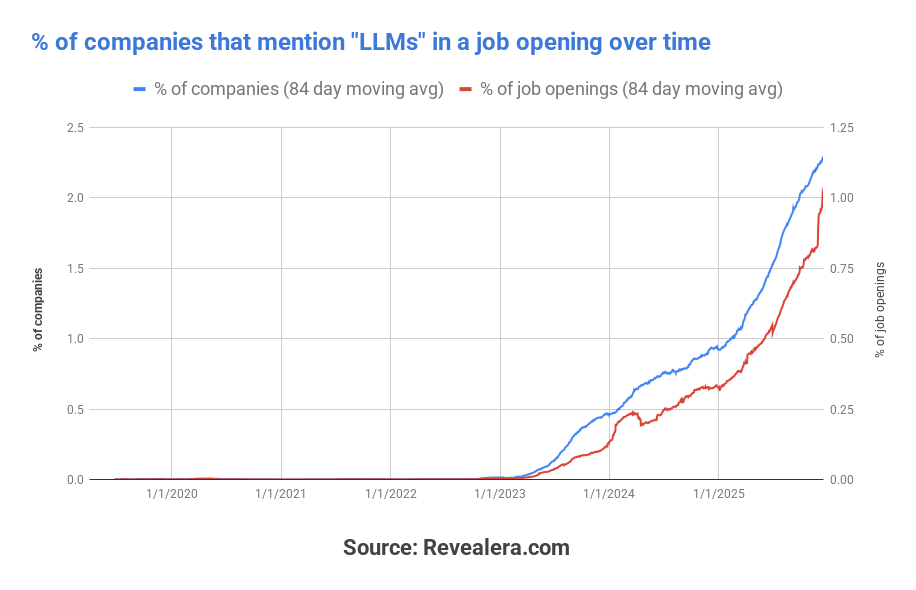
For example, here’s a chart from Revealera that shows how many companies mention the term “LLMs” in a job posting over time.
Where does Revealera get its data?
Revealera crawls company career pages directly – no LinkedIn, no job board aggregators. They also pull from publicly available ATS APIs (like Greenhouse) where freely accessible. They’re transparent about their methodology: no CAPTCHA bypassing, and no authentication circumvention. If a site requires login or CAPTCHA, they simply don’t scrape it.
What sets Revealera apart is their obsessive data quality process. They run automated regression tests daily that compare today’s job counts against yesterday’s for every tracked company.
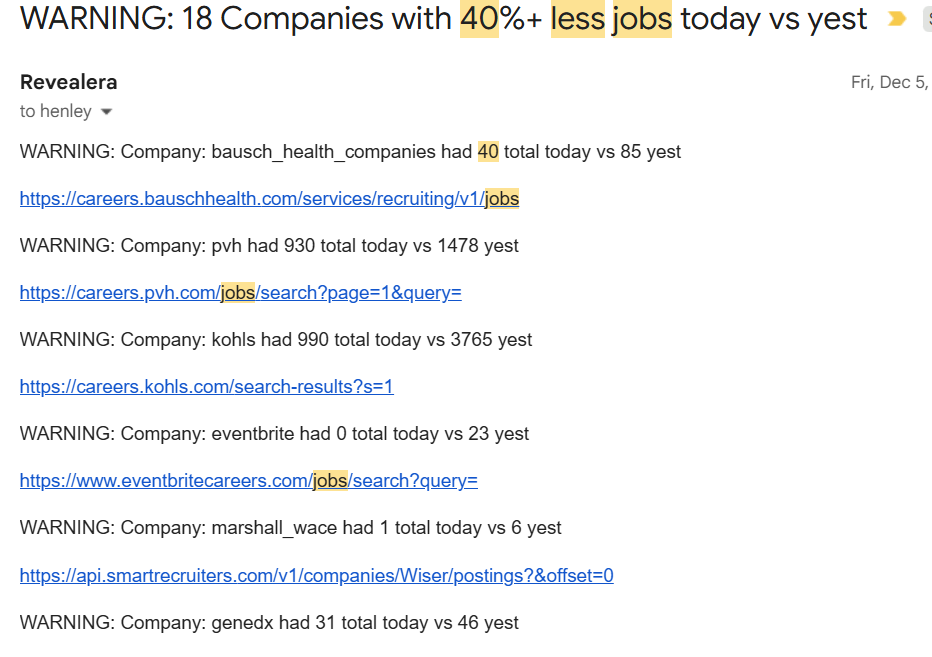
For example, if the # of total jobs for a company drop by 40%+ in one day, the system flags it immediately. They also monitor for companies that haven’t posted new jobs in a week.
That means when companies change their ATS provider or redesign their careers page (a common cause of data gaps), Revealera catches it within a day or two, so they can fix heir extraction method, rather than letting bad data accumulate for weeks.
How does Revealera handle acquisitions?
This is actually well thought out. For major acquisitions (>$1B) where the acquired company has substantial job volume, Revealera folds the acquired company’s postings into the parent going forward. But here’s the key part: historical counts exclude acquired companies by default to maintain apples-to-apples comparisons. You can toggle this on if you want the combined view.
When pulling actual job descriptions (not just counts), acquired company postings are always included but clearly tagged with which subsidiary they belong to.
Coverage and freshness
Revealera tracks ~5,000 companies for hiring data and ~75,000 companies for over 600+ technology mentions. Historical data goes back to late 2018 for most companies. Crawls run daily, with same-day visibility into job posting changes.
How do you access the data?
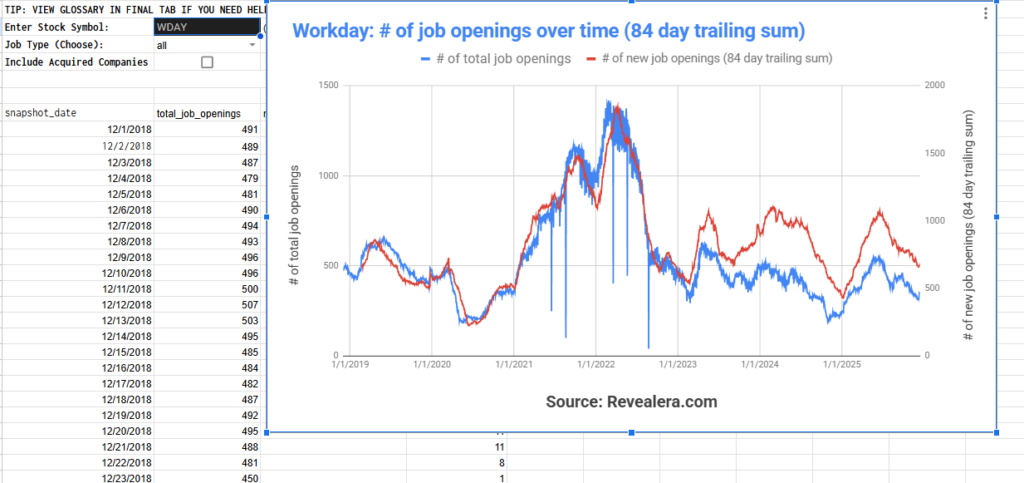
Revealera offers multiple options: daily dumps to S3, REST API, web app or a simple Google Sheets link with pre-built charts and data exploration tools (see screenshot above showing Workday’s hiring trends over time).
Most hedge fund clients opt for daily downloads available through S3. Data is usually available within 1-2 days.
Limitations
The company universe is smaller than enterprise providers – 5,000 tracked companies vs. Lightcast’s hundreds of thousands, but that’s also because Revealera cares a lot more about data quality, as there’s no practical, human way to monitor 100,000 company websites, and fix issues if one of them changes.
If Microsoft or any of those 5000 companies totally restructures their careers website, Lightcast probably will take days to notice and fix the issue (if they even do). When you’re in the hedge fund industry, that type of delay is simply intolerable.
Another limitation is there’s noticeably less enrichment: you won’t get the sophisticated skills taxonomies or occupation classifications that Revelio or Lightcast provides.
How much does Revealera cost?
Pricing isn’t published but it’s reasonable, and cheaper than Lightcast, Revelio Labs, and LinkUp.
Who is Revealera best for?
Quantitative investors and hedge funds who want clean, daily job posting signals for trading strategies. The financial services focus means the product is built for systematic use cases rather than HR analytics.
Conclusion: Which job postings data provider should you choose?
After reviewing all these providers, here’s my take:
If you’re on a tight budget or a sales team: Start with Bloomberry. At $0.006 per posting, it’s the cheapest paid option, and the data is clean because they scrape company websites directly (no LinkedIn reposting noise).
If you need comprehensive workforce intelligence (not just job postings): Revelio Labs offers the most sophisticated workforce analytics – headcount flows, skills taxonomies, AI exposure metrics, expected hires weighting.
If you’re a large enterprise doing workforce planning: Lightcast is the industry standard for a reason. Their skills taxonomy is used across the HR tech ecosystem, and they have the deepest historical data combined with government statistics.
If you’re a hedge fund or quantitative investor: Revealera was built specifically for you. Their obsessive daily QA process means you won’t get blindsided by bad data when a company changes their careers page. The smaller universe (~5,000 companies) is actually a feature – it means they can actually monitor data quality at a human level.


